Spark Jargon for Starters
This blog is to clear some of the starting troubles when newbie codes for Spark distributed computing. Apart from learning the APIs, one needs to equip themselves with cluster details to get best of the Spark power.
The starting point would be Cluster Mode Overview .
And some common questions that might pop up are:
- You still can’t understand the different processes in the Spark Standalone cluster and the parallelism.
- You ran the bin\start-slave.sh and found that it spawned the worker, which is actually a JVM. Is worker a JVM process or not?
- As per the above link, an executor is a process launched for an application on a worker node that runs tasks. Executor is also a JVM.
- Executors are per application. Then what is role of a worker? Does it co-ordinate with the executor and communicate the result back to the driver? or does the driver directly talks to the executor? If so, what is worker’s purpose then?
- How to control the number of executors for an application?
- Can the tasks be made to run in parallel inside the executor? If so, how to configure the number of threads for an executor?
- What is the relation between worker, executors and executor cores ( — total-executor-cores)?
- what does it mean to have more workers per node?
Lets revisit the Spark Cluster mode details.

Spark uses a master/slave architecture. As you can see in the figure, it has one central coordinator (Driver) that communicates with many distributed workers (executors). The driver and each of the executors run in their own Java processes.
DRIVER
The driver is the process where the main method runs. First it converts the user program into tasks and after that it schedules the tasks on the executors.
Spark Application — -> Driver — -> List of Tasks — -> Scheduler — -> Executors
EXECUTORS
Executors are worker nodes’ processes in charge of running individual tasks in a given Spark job. They are launched at the beginning of a Spark application and typically run for the entire lifetime of an application. Once they have run the task they send the results to the driver. They also provide in-memory storage for RDDs that are cached by user programs through Block Manager.
When executors are started they register themselves with the driver and from so on they communicate directly. The workers are in charge of communicating the cluster manager the availability of their resources.
In a standalone cluster you will get one executor per worker unless you play with `spark.executor.cores` and a worker has enough cores to hold more than one executor.
- For example, consider a standalone cluster with 5 worker nodes (each node having 8 cores)
- When i start an application with default settings, Spark will greedily acquire as many cores and executors as are offered by the scheduler. So in the end you will get 5 executors with 8 cores each.
Following are the spark-submit options to play around with number of executors:
— executor-memory MEM Memory per executor (e.g. 1000M, 2G) (Default: 1G).
Spark standalone and YARN only:
— executor-cores NUM Number of cores per executor. (Default: 1 in YARN mode, or all available cores on the worker in standalone mode)
YARN-only:
— num-executors NUM Number of executors to launch (Default: 2). If dynamic allocation is enabled, the initial number of executors will be at least NUM.
- Does 2 worker instance mean one worker node with 2 worker processes?
A node is a machine, and there’s not a good reason to run more than one worker per machine. So two worker nodes typically means two machines, each a Spark worker.
1 Node = 1 Worker process
- Does every worker instance hold an executor for specific application (which manages storage, task) or one worker node holds one executor?
Workers hold many executors, for many applications. One application has executors on many workers
A worker node can be holding multiple executors (processes) if it has sufficient CPU, Memory and Storage.

- BTW, Number of executors in a worker node at a given point of time is entirely depends on work load on the cluster and capability of the node to run how many executors.
APPLICATION EXECUTION FLOW
With this in mind, when you submit an application to the cluster with spark-submit this is what happens internally:
- A standalone application starts and instantiates a SparkContext/SparkSession instance (and it is only then when you can call the application a driver).
- The driver program ask for resources to the cluster manager to launch executors.
- The cluster manager launches executors.
- The driver process runs through the user application. Depending on the actions and transformations over RDDs task are sent to executors.
- Executors run the tasks and save the results.
- If any worker crashes, its tasks will be sent to different executors to be processed again. In the book “Learning Spark: Lightning-Fast Big Data Analysis” they talk about Spark and Fault Tolerance:
Spark automatically deals with failed or slow machines by re-executing failed or slow tasks. For example, if the node running a partition of a map() operation crashes, Spark will rerun it on another node; and even if the node does not crash but is simply much slower than other nodes, Spark can preemptively launch a “speculative” copy of the task on another node, and take its result if that finishes.
- With SparkContext.stop() from the driver or if the main method exits/crashes all the executors will be terminated and the cluster resources will be released by the cluster manager.
If we look the execution from Spark prospective over any resource manager for a program, which join two rdds and do some reduce operation then filter
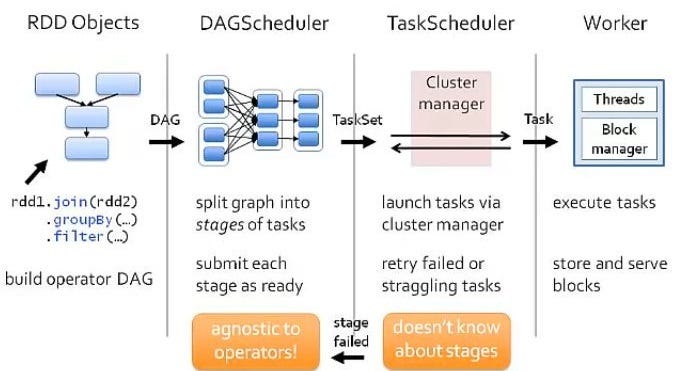
Following list captures some recommendations to keep in mind while configuring them:
- Hadoop/Yarn/OS Deamons: When we run spark application using a cluster manager like Yarn, there’ll be several daemons that’ll run in the background like NameNode, Secondary NameNode, DataNode, JobTracker and TaskTracker. So, while specifying num-executors, we need to make sure that we leave aside enough cores (~1 core per node) for these daemons to run smoothly.
- Yarn ApplicationMaster (AM): ApplicationMaster is responsible for negotiating resources from the ResourceManager and working with the NodeManagers to execute and monitor the containers and their resource consumption. If we are running spark on yarn, then we need to budget in the resources that AM would need (~1024MB and 1 Executor).
- HDFS Throughput: HDFS client has trouble with tons of concurrent threads. It was observed that HDFS achieves full write throughput with ~5 tasks per executor . So it’s good to keep the number of cores per executor below that number.
- MemoryOverhead: Following picture depicts spark-yarn-memory-usage.
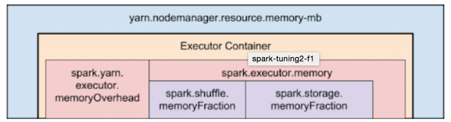
Two things to make note of from this picture:
Full memory requested to yarn per executor =
spark-executor-memory + spark.yarn.executor.memoryOverhead.
spark.yarn.executor.memoryOverhead =
Max(384MB, 7% of spark.executor-memory)So, if we request 20GB per executor, AM will actually get 20GB + memoryOverhead = 20 + 7% of 20GB = ~23GB memory for us.
- Running executors with too much memory often results in excessive garbage collection delays.
- Running tiny executors (with a single core and just enough memory needed to run a single task, for example) throws away the benefits that come from running multiple tasks in a single JVM.
Enough theory.. Let’s go hands-on..
Now, let’s consider a 10 node cluster with following config and analyse different possibilities of executors-core-memory distribution:
**Cluster Config:**
10 Nodes
16 cores per Node
64GB RAM per NodeFirst Approach: Tiny executors [One Executor per core]:
Tiny executors essentially means one executor per core. Following table depicts the values of our spar-config params with this approach:
--num-executors = 16 (In this approach, we'll assign one executor per core total-cores-in-cluster num-cores-per-node * total-nodes-in-cluster 16 x 10 = 160)
--executor-cores = 1 (one executor per core)
--executor-memory = 4GB (amount of memory per executor mem-per-node/num-executors-per-node 64GB/16 = 4GB)Analysis: With only one executor per core, as we discussed above, we’ll not be able to take advantage of running multiple tasks in the same JVM. Also, shared/cached variables like broadcast variables and accumulators will be replicated in each core of the nodes which is 16 times. Also, we are not leaving enough memory overhead for Hadoop/Yarn daemon processes and we are not counting in ApplicationManager. NOT GOOD!
Second Approach: Fat executors (One Executor per node):
Fat executors essentially means one executor per node. Following table depicts the values of our spark-config params with this approach:
--num-executors = 10 (In this approach, we'll assign one executor per node total-nodes-in-cluster 10)
--executor-cores = 16 (one executor per node means all the cores of the node are assigned to one executor total-cores-in-a-node 16)
--executor-memory = 64GB (amount of memory per executor mem-per-node/num-executors-per-node 64GB/1 = 64GB)Analysis: With all 16 cores per executor, apart from ApplicationManager and daemon processes are not counted for, HDFS throughput will hurt and it’ll result in excessive garbage results. Also,NOT GOOD!
Third Approach: Balance between Fat (vs) Tiny
According to the recommendations which we discussed above:
- Based on the recommendations mentioned above, Let’s assign 5 core per executors => — executor-cores = 5 (for good HDFS throughput)
- Leave 1 core per node for Hadoop/Yarn daemons => Num cores available per node = 16–1 = 15
- So, Total available of cores in cluster = 15 x 10 = 150
- Number of available executors = (total cores / num-cores-per-executor) = 150 / 5 = 30
- Leaving 1 executor for ApplicationManager => — num-executors = 29
- Number of executors per node = 30/10 = 3
- Memory per executor = 64GB / 3 = 21GB
- Counting off heap overhead = 7% of 21GB = 3GB. So, actual — executor-memory = 21–3 = 18GB
So, recommended config is: 29 executors, 18GB memory each and 5 cores each!!
Analysis: It is obvious as to how this third approach has found right balance between Fat vs Tiny approaches. Needless to say, it achieved parallelism of a fat executor and best throughput's of a tiny executor!!
Illustration:
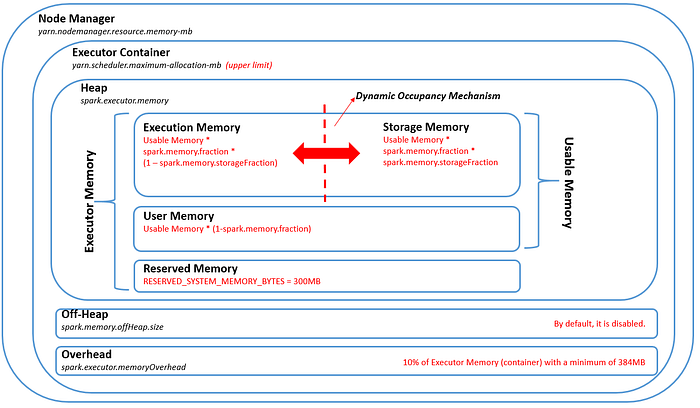
spark.memory.fraction = 0.6
spark.memory.storageFraction = 0.5
Lets see what happens if we request for 14GB with YARN maximum memory allocation of 184GB (spark.executor.memory=14G):
- Overhead : 1.4GB
- Executor memory: 14GB
- Reserved memory : 300 MB
- Usable memory: 14–0.3 = 13.7GB
- User memory: 13.7 * (1–0.6) = 5.48GB
- Storage/Execution Memory: 13.7–5.48 = 8.22 GB
After all the bribe we end up with 8.22GB/executor usable memory!
If the cluster manager is YARN, then have a look at following configuration for proper resource utilization metrics in UI, otherwise the reported cores used wont match the requested spark cores.
- yarn.scheduler.capacity.resource-calculator If you are using YARN as cluster manager, then this is a must change configuration to DominantResourceCalculator to get correct container information on YARN UI
- org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator only uses Memory and ignores the cores requested for!
- org.apache.hadoop.yarn.util.resource.DominantResourceCalculator uses Dominant-resource to compare multi-dimensional resources such as Memory, CPU etc.
A similar blogs on Spark configuration on cores and memory :
Conclusion:
We’ve seen:
- Couple of recommendations to keep in mind which configuring these params for a spark-application like:
- Budget in the resources that Yarn’s Application Manager would need
- How we should spare some cores for Hadoop/Yarn/OS deamon processes
- Learnt about spark-yarn-memory-usage
- Also, checked out and analyzed three different approaches to configure these params:
- Tiny Executors — One Executor per Core
- Fat Executors — One executor per Node
- Recommended approach — Right balance between Tiny (Vs) Fat coupled with the recommendations.
— num-executors, — executor-cores and — executor-memory.. these three params play a very important role in spark performance as they control the amount of CPU & memory your spark application gets. This makes it very crucial for users to understand the right way to configure them. Hope this blog helped you in getting that perspective…
